Why LLM Gateway Attribution Is Harder Than Cloud FinOps Ever Was
Cloud FinOps had two stable attribution units. LLM spend has N freeform dimensions, two failure modes nobody talks about, and a hidden cost in reporting UX.
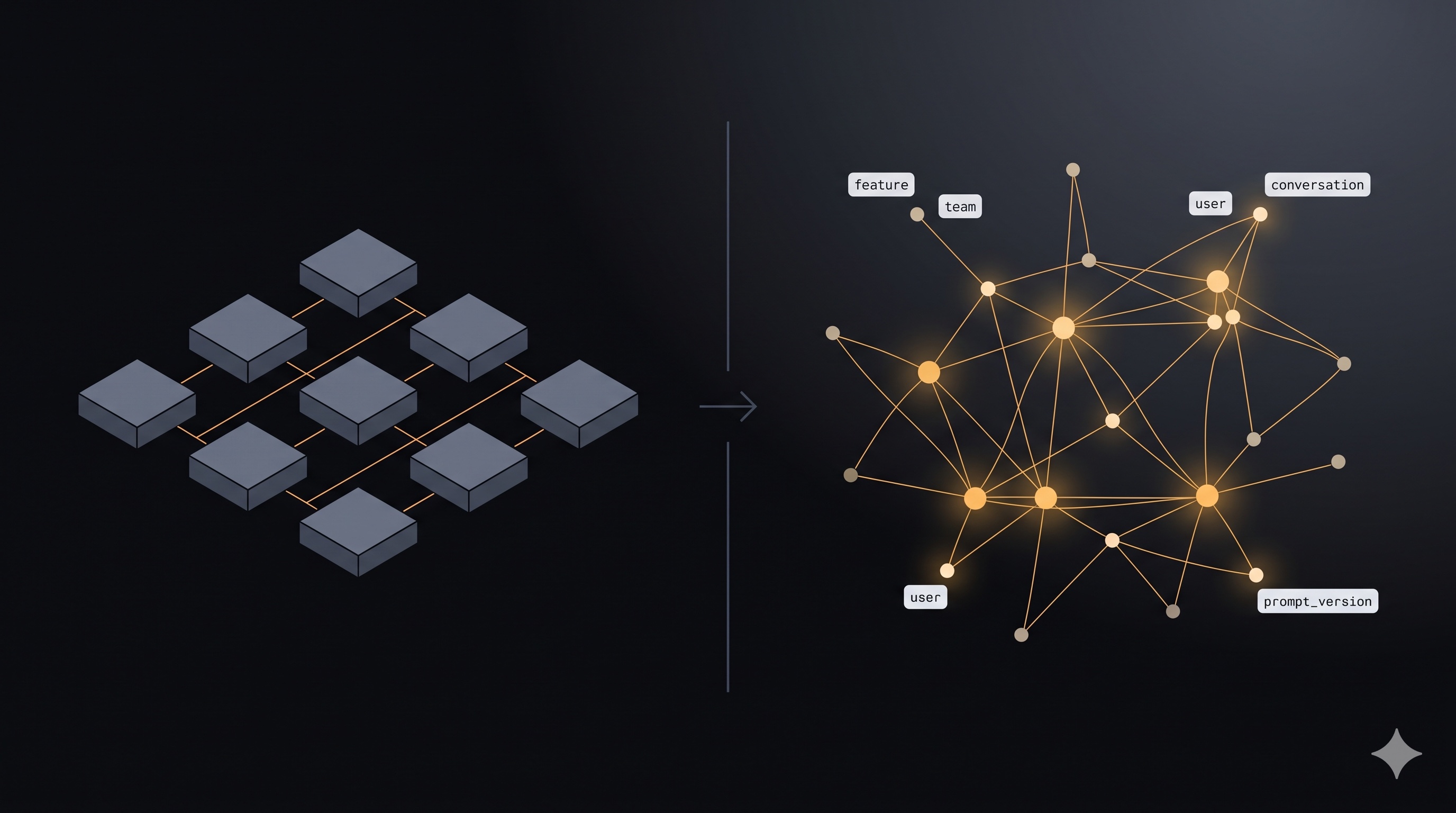
Cloud FinOps had it easy. The attribution units were stable, the dimensions were small, and the people who had to agree on what “cost per tenant” meant could usually agree in one meeting. By 2015 the discipline was solved well enough that CloudHealth, Apptio, and a handful of others had built mature tools around the same five or six pivot axes everybody used.
LLM gateway attribution is not that. It’s not even close.
I run an AI gateway in production (Prism) and write about cost discipline (LLM FinOps), and the question I get most often from other founders building gateways or evaluating them is some variant of: “how do I attribute this cost properly?” Two dev.to comments this week — one on a gateway comparison post and one on the LLM FinOps explainer — crystallized why the question is harder than it looks.
This post is the answer I wish someone had written for me before I built the gateway.
TL;DR
| What | Why it matters | |
|---|---|---|
| Cloud FinOps had | 5-6 stable attribution units (instance, tenant, project, region, service) | Tools could pre-build fixed dashboards around them |
| LLM has | N open-ended dimensions (feature, team, user, conversation, prompt-version, experiment) | Fixed-column dashboards break the moment a caller invents a new dimension |
| Failure mode 1 | Hop loss: context fields drift across gateway → downstream hops | Per-feature attribution looks right but is wrong, silently |
| Failure mode 2 | Wrong unit: gateway forces caller to pick one primary unit upfront | Every analysis that needs a different unit is broken from day one |
| Right answer | Deterministic auth anchors + freeform tag bag, both in one canonical row | Different stakeholders pivot on what they care about, no drift |
| Hidden cost | Reporting UX, not storage | Faceted discovery is harder engineering than three opinionated columns |
Why cloud FinOps had it easy
In 2014, when cloud FinOps emerged as a discipline, the attribution problem was already shaped by the providers themselves. AWS billing exposed costs along a fixed set of axes: account, region, service, instance type, tag. Tags were freeform but capped at fifty per resource. The cardinality of useful pivots was small. Most companies converged on three or four primary dimensions: tenant ID for SaaS, team ID for internal cost recovery, environment for dev/staging/prod splits, and region for compliance reporting.
Tools like CloudHealth, Apptio, and Vantage could pre-build dashboards around these because the dimensions were known in advance and stable. New attribution axes appeared rarely — maybe one a year, usually when AWS launched a new service. The build cost of supporting “the new dimension” was amortized across a thousand customers.
LLM attribution is a different shape entirely.
The cost driver is tokens, not compute hours. Tokens scale non-linearly with usage patterns. Output tokens are uncapped by default. Models switch underneath you. Retry semantics differ across providers. None of this maps cleanly onto cloud cost models, but the deeper problem is the attribution dimensions themselves.
A startup using an LLM gateway typically wants to slice cost along axes like: per-feature (“how much does our onboarding flow cost?”), per-team (“growth versus product engineering”), per-end-user (“this enterprise customer is 40% of our spend”), per-conversation (“what’s the average cost of a support session?”), per-prompt-version (“did the v3 prompt actually reduce cost like we expected?”), per-experiment (“the A/B variant added 12% to per-request cost”), per-model (“Claude vs GPT-4 split”), and increasingly per-agent-loop (“the auditor agent is burning more than the writer agent”).
That’s eight dimensions, none of which are stable across companies, none of which AWS-style billing systems were designed for, and most of which the gateway has no visibility into unless the caller explicitly tells it.
This is the surface area cloud FinOps tools never had to deal with. It’s also why the existing cloud FinOps vendors treat AI spend as a single line item rather than decomposing it. They don’t have the dimensional model for it.
Failure mode 1: hop loss
The first failure mode is silent and almost nobody talks about it in public, but it shows up the moment you try to debug an attribution number that “doesn’t add up.”
When a request flows through an LLM gateway, it typically goes through at least two hops:
client → edge worker → origin router → providerAt each hop, the request can carry context fields — typically headers like X-Workflow-Id, X-Conversation-Id, or a tag header like X-Tags: feature=onboarding,team=growth. The question is: do these fields survive intact across hops, or does each hop re-derive them from the request?
If each hop re-derives, you have a dual-writer pattern, and the writers can drift. Edge logs one value for feature. Origin logs a different value because it parses the header slightly differently, or because it pulls feature from a different source like the URL path. Now you have two rows in your usage_logs table that disagree about what the request was attributed to. Your per-feature attribution numbers are silently wrong.
The competitor-founder who flagged this on the Portkey gateway comparison post called the pattern “hop loss” and built a tiny diagnostic tool around it. The framing is precise: the field survives the request, it just drifts in transit.
This pattern is real and worth checking your gateway for. The fix is to make exactly one layer the parser-and-writer of attribution fields. Every other layer forwards the request untouched. In Prism, the edge worker reads only auth and routing headers, then forwards the request object as-is to origin. Origin is the sole parser of attribution fields and the sole writer to usage_logs. Zero drift surface because there’s only one writer.
But.
There’s an adjacent failure mode that hop-loss-the-framing doesn’t quite capture: the single-writer-drops-the-row problem. When the edge serves a cached response without ever reaching origin, no usage_logs row gets written at all. The cached request gets counted in an aggregate Redis counter keyed by account and date, but the per-feature, per-tag, per-user breakdown is invisible for that slice.
For a workload with 30-60% cache hit rate, that’s a meaningful slice of traffic where attribution is aggregate-only. Not “the field drifted.” The field disappeared entirely.
I knew this gap existed in Prism the moment the comment landed; I’d seen the cache-hit path and the origin-write path live in two different layers and never reconciled them. The fix is ~80 LOC: have the edge worker also write a usage row when it serves a cache hit, fired from ctx.waitUntil() so the customer’s response latency stays sub-100ms. It’s been bumped to v1.8.
The general lesson: before you trust an attribution dashboard, ask which layer writes the canonical row, and whether every code path that serves the customer also fires that write. It’s a one-line audit that catches more attribution bugs than any tool.
Failure mode 2: the wrong unit
The second failure mode is the one Void surfaced on the LLM FinOps post. Cost attribution at the request level is technically solvable. The harder problem is: what’s the right attribution unit?
Teams want per-feature, because that’s how product roadmaps are organized. Finance wants per-team, because that’s how budgets are owned. Customer success wants per-user, because that’s how account health is measured. Engineering wants per-conversation-or-experiment, because that’s how they reason about prompt changes.
These are not the same unit. They’re not interchangeable. And a gateway that bakes in one primary unit will break the moment a stakeholder shows up wanting a different one.
This is where I see most gateways make their fatal design choice. The path of least resistance is to pick the most “obvious” attribution unit (usually per-feature or per-tenant) and bake it into the schema. usage_logs.feature_name VARCHAR(100). Done in fifteen minutes. Then six months later, finance wants per-team rollups, you don’t have team data on the rows, and you’re either back-filling from a join table that doesn’t exist or telling finance their question isn’t answerable.
The gateways that survive contact with multiple stakeholders make a different choice: they accept that attribution is fundamentally multi-dimensional and they push the dimension definition out to the caller.
The right model: deterministic anchors + freeform tag bag
The model that works in production splits attribution into two layers:
Layer 1: deterministic anchors from auth. When the request comes in with an API key, the gateway looks up the key and derives project_id and org_id. These are immutable per-request facts. They land in the canonical row with no caller input required. They’re the floor of attribution — every request has them, every report can rely on them.
Layer 2: freeform tag bag from the caller. The gateway exposes a single header like X-Tags: feature=onboarding,team=growth,user=u_123,prompt_version=v3 and parses it into a jsonb column on usage_logs. Whatever the caller wants to track, they put in the header. The gateway doesn’t care what dimensions exist — it just stores them.
Both layers land in a single canonical row per request. Querying becomes a GROUP BY on whichever dimension the asker cares about that day:
-- Finance: cost by org
SELECT org_id, SUM(cost_usd) FROM usage_logs
WHERE date BETWEEN '2026-05-01' AND '2026-05-31'
GROUP BY org_id;
-- Product: cost by feature
SELECT request_tags->>'feature' AS feature, SUM(cost_usd) FROM usage_logs
WHERE date BETWEEN '2026-05-01' AND '2026-05-31'
GROUP BY request_tags->>'feature';
-- Customer success: cost by enterprise user
SELECT request_tags->>'user' AS user_id, SUM(cost_usd) FROM usage_logs
WHERE org_id = 'org_acmecorp'
GROUP BY request_tags->>'user'
ORDER BY 2 DESC LIMIT 50;Same canonical row. Three different slices. No schema migrations. No “we can’t answer that question, the data wasn’t captured.”
This is roughly what Prism ended up doing after I tried two opinionated approaches that broke as soon as I had three customers with three different mental models of attribution. It’s also roughly what Portkey, Helicone, and the more thoughtful LiteLLM deployments do under the hood.
The reason it’s not the universal default is that handing the caller N freeform dimensions creates a different problem downstream: reporting.
The hidden cost: reporting UX
The non-obvious cost of multi-dimensional attribution isn’t storage. jsonb columns scale fine. Postgres handles a billion rows of request_tags without breaking a sweat. The cost is reporting UX.
Fixed-column dashboards are easy to build. You know in advance that your table has feature_name, team_name, user_id. You render a fixed report with three filter dropdowns. Done.
Faceted dashboards over a freeform tag bag are much harder. You don’t know in advance what tag keys exist. You have to enumerate them at query time: “what distinct keys appeared in request_tags in the last 30 days?” That enumeration becomes the filter UI. New keys appear as new filter chips automatically. Old keys that nobody uses age out.
This is conceptually similar to faceted search (think Algolia or Elastic) but applied to cost attribution. It’s well-understood engineering, but it’s a meaningful amount of engineering. Most gateway dashboards today still render fixed columns because faceted discovery is harder to build than three opinionated dropdowns.
The trade-off:
| Approach | Storage | Schema migrations | Dashboard | Adds new dimension |
|---|---|---|---|---|
| Fixed-column attribution | Easy | Frequent | Easy to build | Schema change + UI rebuild |
| Freeform tag bag + faceted UI | Easy | None | Harder to build | Caller just adds the tag, UI surfaces it automatically |
If you’re building a gateway and choosing between these two approaches, the freeform tag bag wins on every axis except initial dashboard engineering effort. That’s the trade most teams get wrong because they don’t see the medium-term cost of the schema-migration loop.
What to demand of your gateway
If you’re not building a gateway but evaluating one, here’s the checklist that separates serious attribution from cosmetic attribution. Run this against your current or candidate gateway:
Single canonical row per request, written by exactly one layer. Ask the vendor: “which component writes the canonical usage row, and does every request path including cache hits and retries fire that write?” If they can’t answer immediately, attribution is probably broken in at least one path.
Auth-derived anchors are immutable per request. org_id, project_id, or whatever the gateway calls them, must be derived from the API key at auth time and travel with the request. Not derived from the URL. Not parsed from a header. Auth-time derivation is the only thing that can’t be spoofed or accidentally re-derived to a different value downstream.
Freeform multi-dimensional tags supported via a single ingress header. Bonus points if the column is jsonb (so dimensions are queryable) and not a flat string (so they’re not).
Faceted dashboard or at minimum a SQL escape hatch. If the dashboard renders fixed columns, you’ll outgrow it. Make sure you can query the underlying table directly when the built-in views fail you.
Per-request cost is reconcilable to provider invoices. This is the one most gateways quietly fail. Sum the per-request costs across a billing period and compare against the provider’s invoice. If they’re off by more than 2%, something in the cost model is wrong — either token counts, model prices, or both.
Retries and fallbacks are captured as distinct rows. When the gateway retries a failed request or falls back to a secondary model, each attempt should be its own usage row tagged with parent_request_id and attempt_number. Otherwise retry storms become invisible cost spikes.
Streaming requests are captured at completion with full token counts. Streaming surfaces (Server-Sent Events) require the gateway to count tokens after the stream closes, not at request start. Plenty of gateways drop streaming attribution entirely or count input-only.
Why this matters now
LLM spend is at the 2014 cloud moment — bills are growing 10x year-over-year at companies that have AI in production, the existing FinOps tools weren’t designed for it, and the gateway layer is the only place attribution can live cleanly. The teams that get this right early will have clean unit economics conversations a year before the teams that didn’t.
If you’re building a gateway, the design lesson is: don’t pick a primary attribution unit. Push the choice to the caller, give them deterministic anchors plus a freeform tag bag, and pay the reporting-UX tax to make faceted discovery work. The teams that picked a winner are the ones being asked to rebuild their attribution layer eighteen months later.
If you’re using a gateway, the audit lesson is: single canonical row, every code path writes it, anchors are auth-derived, tags are queryable. Run those four checks against whatever you’re using today. Most gateways pass on two or three but fail on at least one.
If you’re building cost tooling on top of a gateway you don’t control, the practical lesson is: don’t trust the dashboard, trust the underlying usage table. Every serious gateway exposes it via export, API, or SQL. Build your reporting from the raw rows. The dashboards are the demo; the table is the truth.
What’s next
This post focused on the attribution layer specifically. The adjacent topics worth your time if you’re thinking about LLM cost discipline more broadly:
- What is LLM FinOps? — the broader discipline this fits inside
- Portkey vs Helicone vs LiteLLM vs OpenRouter — honest comparison of the gateway landscape
- How I run 3 production AI SaaS on $5/month — the cost side of the story, with numbers
If you want to see what the right model looks like in production code, Prism is the gateway I built around the principles in this post. The attribution model described above is roughly how it ships today, minus the cache-hit gap I just publicly committed to fixing.